Source
Lacoste, A., Luccioni, A., Schmidt, V., & Dandres, T. (2024). Evaluating the Carbon Footprint of Language Models. Generative AI Pub. Disponible ici.
Résumé
L’entraînement et l’utilisation des modèles de langage consomment d’énormes quantités d’énergie, soulevant des questions environnementales critiques. Cet article analyse l’empreinte carbone des modèles d’IA, les facteurs influençant leur consommation énergétique et les stratégies pour réduire leur impact.
Points clés
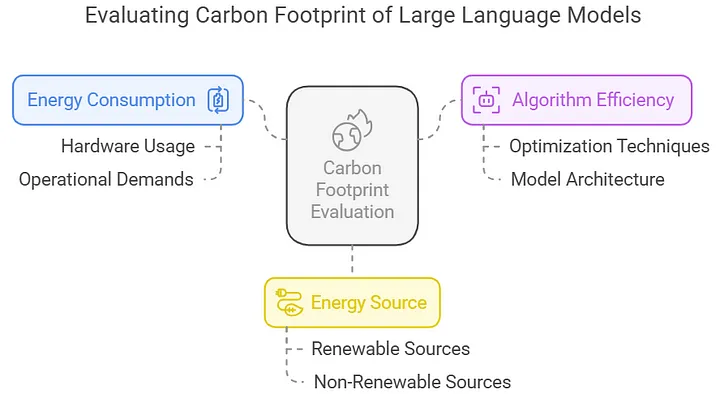
- Consommation énergétique croissante : L’entraînement des modèles comme GPT-4 nécessite des milliers de GPU fonctionnant durant des semaines, entraînant une empreinte carbone importante.
- Facteurs d’influence : Le type d’architecture, la source d’électricité (énergies fossiles vs renouvelables) et l’efficacité des algorithmes impactent les émissions de CO₂.
- Solutions techniques : Optimisation des algorithmes, quantification des modèles et recours aux énergies renouvelables permettent de limiter les émissions.
- Approche responsable : Les chercheurs recommandent une transparence accrue sur l’empreinte carbone et le développement de modèles plus économes en énergie.
Valeur ajoutée pour l’éducation
- Sensibilisation aux impacts de l’IA : Intégrer ces enjeux dans les formations en IA pour développer une approche plus durable.
- Choix technologiques éclairés : Encourager l’adoption de solutions énergétiquement efficientes dans les institutions éducatives.
- Engagement institutionnel : Favoriser l’utilisation d’IA alimentées par des sources d’énergie verte dans les plateformes éducatives.